Error Handling in the Practical Type System (PTS)
|
First Published |
2024-02-29 |
|
Author |
Christian Neumanns |
|
Editor |
Tristano Ajmone |
|
License |
This is part 6 in a series of articles titled How to Design a Practical Type System to Maximize Reliability, Maintainability, and Productivity in Software Development Projects.
It is recommended (but not required for experienced programmers) to read the articles in their order of publication, starting with Part 1: What? Why? How?.
For a quick summary of previous articles you can read Summary of the Practical Type System (PTS) Article Series.
Note
Please be aware that PTS is a new paradigm and still a work-in-progress. As explained in section History of the article Essence and Foundation of the Practical Type System (PTS), I created a proof-of-concept implementation which is now a bit outdated — therefore you won’t be able to try out the PTS code examples shown in this article.

Introduction
Do you like to write code that handles errors?
Most programmers (including myself) don't. We prefer coding "the happy path" — handling errors is "no fun." We hope that our applications will run in a world where required files always exist, databases never fail, network connections are always available, and malicious people are unheard of.
Practice shows that error-handling is often neglected (especially in the early stages of a project), because it requires a good deal of dedication, discipline, experience, and expertise. A common pitfall is to think that error-handling "can be done later," since this too often means that it'll never be done, because "there are deadlines, and we need and want to add features."
At the same time, we're also aware of the importance of error-handling, because it helps to identify and resolve issues quickly. Good error-handling is critical for creating software that is reliable, robust, secure, fault-tolerant, maintainable, and user-friendly.
To put it shortly: Error-handling is important, but nobody wants to do it!
Therefore, a type system designed for reliability should:
-
protect us from accidentally forgetting to handle errors
-
facilitate all error-handling variations as much as possible (including explicitly ignoring errors), and support a succinct syntax that is easy to read and write
This article shows how PTS aims to achieve this.
Common Error-Handling Approaches
Before showing how error-handling works in PTS, it might be useful to first consider some common error-handling approaches.
Note
Readers only interested in the PTS approach can skip this section.
Here's a brief summary:
-
Dedicated Return Value(s)
In langues without native support for error-handling, a dedicated return value can be used to signal an error.
For example:
-
A function returning an integer greater or equal to 0, returns
-1in case of an error. -
A function that converts an XML document into a JSON string returns
"XML ERROR"if the XML document could not be parsed, or"JSON ERROR"if the JSON document couldn't be created.
A special case of this approach is to return a boolean value indicating success or failure.
-
-
Mutable Input Parameter
Another way to return errors in languages without built-in error-handling support is to use a mutable input parameter that can be set to an error value inside the function, and then be explored in code that invoked the function.
-
Global Error Object
A few languages provide a global read/write error object that's updated by a function to signal an error, and then read by parent functions in the call stack to check whether an error occurred.
An example is
errnoin C. -
Multiple Return Values
Some programming languages support multiple return values in functions. The first output parameter(s) are used to return a result, while the last output parameter is used to return an error. Golang uses this approach.
A similar effect can be achieved with tuples returned by functions.
-
Exceptions
Many popular programming languages support exceptions as a dedicated mechanism for handling errors — for example C++, C#, Java, JavaScript, Kotlin, Python, and Ruby.
As far as I know, Java is the only popular language that differentiates between checked and unchecked exceptions. Unchecked exceptions can be ignored, but checked exceptions can't. All other languages listed above use only unchecked exceptions.
-
Result/EitherTypeSome languages provide a
Result(akaEither) type, which can be used as the return type of a function that might fail. There are two possible instances for this type: an instance representing a successful return value, or an instance representing an error.For example:
Note
For a thorough discussion of most error-handling approaches listed above, I recommend reading Joe Duffy's article The Error Model.
Examples of the above approaches are also shown in Nicolas Fränkel's article Error handling across different languages.
PTS doesn't adopt any of the above approaches.
The first three approaches (dedicated return value, mutable input parameter, and global error object) are poor ones — they lead to error-prone error-handling, and they are therefore inappropriate in high-level languages designed to write reliable code.
Using multiple return values or tuples for error handling isn't developer-friendly. Errors can easily be ignored, and the code quickly becomes cluttered with error-handling.
The main reasons for not using exceptions or a Result/Either type in PTS are explained in section Why Do We Need Union Types? of the article Union Types in the Practical Type System (PTS).
Note
Other reasons for not adopting unchecked exceptions to handle all errors can be found in section Unchecked Exceptions of Joe Duffy's (long but very insightful) article The Error Model
How Does It Work?
This section provides an overview of error-handling in PTS, illustrated by simple source code examples, but without delving into implementation details.
Fundamental Principles
A crucial principle in PTS is to distinguish between two types of errors:
-
anticipated errors, for example
file_not_found_error,network_connection_error, etc.These errors are expected to possibly occur at run-time.
-
unanticipated errors, for example
out_of_memory_error,stack_overflow_error, etc.These errors are not expected to occur at run-time. They occur only if there is a serious problem that can't usually be solved at run-time.
Both types of errors are handled differently.
Anticipated errors are governed by the following principles:
-
Functions that might fail at run-time must state in their signature that an anticipated error might be returned.
-
Errors returned by functions cannot be silently ignored: They must be handled in the calling code, or ignored explicitly.
-
There is only one idiomatic way to return errors from functions, but there are several (well supported) ways to handle errors returned by functions.
-
A dedicated set of operators and statements facilitates error-handling.
Unanticipated errors are governed by the following principles:
-
Unanticipated errors can potentially occur at any time during program execution, and at any location in the source code. However, they are not expected to occur — they are unanticipated, and therefore not declared in function signatures.
-
By default, unanticipated errors are handled by a global error handler. A built-in, default implementation of this handler writes error information (including stack traces) to the standard OS
errdevice and then aborts program execution with exit code1.An application can register different error handlers to customize global handling of unanticipated errors.
-
Unanticipated errors can be caught explicitly anywhere in the source code, in order to provide customized error handling in specific situations.
-
Unanticipated errors are usually thrown implicitly, but they can also be thrown explicitly, for example in case of an unrecoverable problem detected at run-time.
These are the fundamental design principles.
Now let's look into details.
Types
Type Hierarchy
In section Type Hierarchy of the previous article Null-Safety in the Practical Type System (PTS) we already saw the following top types in the PTS type hierarchy:

We'll now refine this type hierarchy, first by defining the sub-types of non_null:
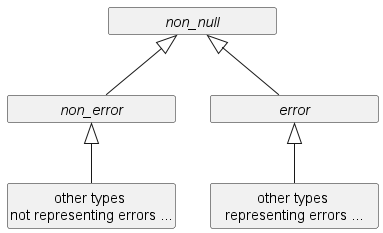
As you can see, there is a clear separation between types that represent errors (child-types of error), and those that don't (child-types of non_error).
Now let's look at the sub-types of error:

This diagram shows the distinction between anticipated and unanticipated errors.
Taking into account the above additional types, the PTS top-types hierarchy becomes:
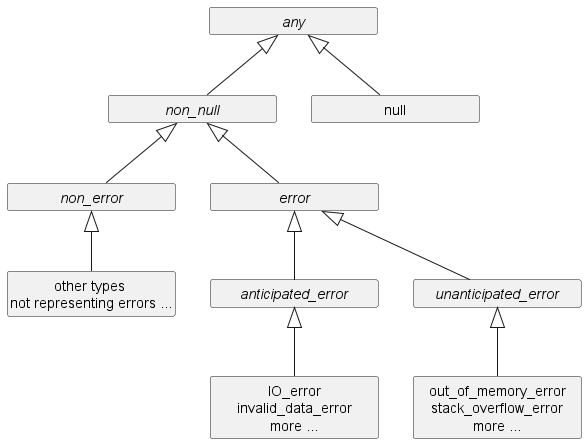
All types displayed in italics are non-instantiable types (aka abstract types). Their cardinality is zero.
Now let's have a closer look at these types.
Type error
Type error is the root of all types representing errors.
error is a non-instantiable (aka abstract) type — its cardinality is zero. Hence, it's impossible to create an object of type error — only concrete descendants of error can be created, such as file_not_found_error and invalid_user_input_error.
Type error is also sealed. It has a fixed set of two direct child-types: anticipated_error and unanticipated_error. Nobody is allowed to define additional direct child-types of error.
Types representing errors all provide specific, structured data about the error — useful information to handle errors and report them appropriately. Type error defines four common attributes, inherited by all its descendants: message, id, time, and cause.
Taking into account the above specifications, type error is defined as follows (using PTS syntax):
type error
inherit: non_null (1)
child_types: anticipated_error, unanticipated_error (2)
factories: none (3)
atts
message string (4)
id string (pattern = "[a-zA-Z0-9_-\.]{1,100}") or null default:null (5)
time date_time or null default:date_time.now (6)
cause error or null default:null (7)
.
.(1) Type error is a child of non_null.
(2) The child_types property defines the fixed set of direct child-types for error: anticipated_error and unanticipated_error. Thus, type error is sealed. It's invalid to define other direct child-types. Moreover, the compiler checks that anticipated_error and unanticipated_error are actually defined in the library.
(3) factories: none declares type error to be a non-instantiable (abstract) type.
(4) Attribute message is required. It holds a description of the error, typically displayed when an error occurs at run-time.
(5) id is an optional string identifier for the error (e.g. "FILE_NOT_FOUND").
(6) time represents the time at which the error occurred. By default, the current date and time is used. This attribute can be set to null in security-sensitive environments where the time must not be stored (e.g. an attacker shouldn't know at which time an error occurred).
(7) cause is an optional attribute representing the lower-level error that caused this error. For example, the cause of a config_data_not_available_error could be a file_not_found_error.
Type non_error
Type non_error is the root of all types that don't represent errors. Descendants comprise:
-
built-in PTS types, such as
string,number,boolean,list,set,map -
user-defined types, such as
customer,supplier,product
Like error, non_error is also non-instantiable and sealed. The fixed set of child-types depends on the PTS implementation, but typical child-types would be: scalar, collection, record, object, and function.
Type anticipated_error
An anticipated error is an error that is expected to possibly occur at run-time.
For example, consider an application that relies on configuration data stored in a file. There is no guarantee that the file will actually exist at run-time — it might have been moved, renamed, or deleted accidentally. We have to anticipate this problem, and handle it accordingly (if we want to write high-quality code). For example, we might display a helpful error to the user and ask if he/she wants to continue with a hard-coded default configuration.
The sub-tree of anticipated_error depends on the PTS implementation. Examples of descendants could be:
-
all kinds of resource input/output errors (e.g.
file_error,directory_error,database_connection_error— all child-types ofIO_error) -
invalid_data_error,user_input_error,compiler_diagnostic_error,unit_test_error, etc.
Type unanticipated_error
An unanticipated error is an error that is not expected to occur at run-time — if it does occur, it means that something really bad happened.
A few examples are: hardware malfunction, a problem in the OS, a configuration issue (e.g. missing library), a bug in the code.
Built-in Child-Types of error
As mentioned already, a PTS implementation provides a built-in set of commonly used descendants of anticipated_error and unanticipated_error.
Descendant types may define additional attributes to those defined in type error, in order to provide specific, structured data related to the error. For instance, type unanticipated_error has the call_trace attribute — a list of source code locations representing the function call stack (very useful for debugging purposes).
If PTS is implemented in an object-oriented language, useful methods can be added too.
As an example, let's look at type file_error, a native descendant of anticipated_error which adds attribute file_path and method file_name, so that we are able to report which file caused the error:
type file_error
inherit: IO_error
att file_path file_path
// Get the name of the file, without it's directory
fn file_name -> file_name
return file_path.name
.
.Types file_not_found_error, file_read_error and file_write_error simply inherit from file_error:
type file_not_found_error
inherit file_error
.
type file_read_error
inherit file_error
.
type file_write_error
inherit file_error
.User-Defined Child-Types of error
Most applications, libraries, and frameworks will define customized descendants of anticipated_error — specific error types related to the project domain.
For example, the API of a stock trading application might return a dedicated unsupported_currency_error for currencies not supported in the trading system.
PTS also allows to define customized descendants of unanticipated_error. However, these are rarely needed — only in special error-handling situations, as exemplified later in this article.
Anticipated Errors
If a function be advertised to return an error code in the event of difficulties, thou shalt check for that code, yea, even though the checks triple the size of thy code and produce aches in thy typing fingers, for if thou thinkest "it cannot happen to me", the gods shall surely punish thee for thy arrogance.
— Henry Spencer, The Ten Commandments for C Programmers
In this section we'll explore anticipated errors — i.e. errors that are expected to possibly occur at run-time (e.g. file_not_found_error, user_input_error, etc.).
Section Fundamental Principles stated:
-
Functions that might fail at run-time must state in their signature that an anticipated error might be returned.
-
Errors returned by functions cannot be silently ignored: They must be handled in the calling code, or ignored explicitly.
The following sections explain how PTS ensures these conditions.
Function Signature
Consider a function that reads text stored in a file. In an ideal world, where such a function would never fail, the code could look like this:
fn read_text_file ( file_path ) -> string
// body
.This function takes a file_path as input, and returns a string representing the text stored in the file.
But in the real world, resource input/output operations are never guaranteed to succeed — failures must be anticipated. Therefore, this function must return an error if the file can't be read for whatever reason (e.g. it doesn't exist, it's locked, it's denied read access, etc.). As explained in the article Union Types in the Practical Type System (PTS), functions that might fail return a union type containing a member of type anticipated_error. In our example, a file_read_error is returned in case of failure. Hence, the function signature must be changed to:
fn read_text_file ( file_path ) -> string or file_read_error
// body
.Now the function returns a string in case of success, or a file_read_error in case of failure.
What should the function return if the file is empty? For reasons explained in a subsequent article, the function doesn't return an empty string — it returns null. The final function signature becomes:
fn read_text_file ( file_path ) -> string or null or file_read_error
// body
.Returning Errors from Functions
Errors are returned from functions like any other value: via a return statement.
Below is an example of a function that asks the user to enter a title. If the user fails to do so, a user_input_error is returned.
fn ask_title -> string or user_input_error
case type of GUI_dialogs.ask_string ( prompt = "Please enter a title" )
is string as title
return title
is null
return user_input_error.create (
message = "A title is required."
id = "INVALID_TITLE" )
.
.Helpful Operators, Statements, and Compiler Features
In the previous articles Union Types in the Practical Type System (PTS) and Null-Safety in the Practical Type System (PTS) the following operators and statements were introduced:
-
statements:
case type of(also available as an expression),assert, and clauseon
We also peeked at some useful compiler features, such as Flow-Sensitive Typing, which reduces the number of type checks needed in the code.
In PTS, null-handling and error-handling share many similarities, and both rely heavily on union types. Therefore, the above mentioned operators and statements are also useful for error-handling — they facilitate our task and enable us to write succinct code. They are available for other types too (not just for null and error), but this article focuses on how to use them in the context of error-handling.
Here is a reiteration of some examples explained in the previous articles:
case type of read_text_file ( file_path.create ( "example.txt" ) )
is string as text // the string is stored in constant 'text'
write_line ( "Content of file:" )
write_line ( text ) // the previously defined constant 'text' is now used
is null
write_line ( "The file is empty." )
is file_error as error
write_line ( """The following error occurred: {{error.message}}""" )
.const message = case type of read_text_file ( file_path.create ( "example.txt" ) )
is string: "a string"
is null: "null"
is error: "an error"
write_line ( "The result is " + message ) Operator ? (safe navigation operator):
const phone_number = get_employee()?null?error \
.get_department()?null?error \
.get_manager()?null?error \
.get_phone_number()assert statement with is operator:
assert result is not errorconst value = get_value_or_null_or_error() \
on null : return null \
on error as e : return eThe above code can be shortened to:
const value = get_value_or_null_or_error() ^null ^errorError Handling Approaches
As stated, anticipated errors returned by functions cannot be silently ignored — we can't accidentally forget to handle them. This (compiler-enforced) rule contributes to more reliable software.
We're now going to explore the following common error-handling approaches:
-
handle the error
-
return (propagate) the error
-
return a wrapper error
-
throw an unanticipated error
-
abort program execution
-
explicitly ignore the error
Note
You can skip this (rather long) section and read it later if you wish.
To illustrate each approach, we'll call a function that takes a customer identifier as input, and returns the name of the customer. If the customer doesn't exist, an error is returned. Here's the function signature:
fn customer_name_by_id ( id string ) -> string or inexistant_customer_errorType inexistant_customer_error is an application-specific error defined as follows:
type inexistant_customer_error
inherit invalid_data_error
att customer_id string
.A dummy implementation of function customer_name_by_id for test purposes could look like this:
fn customer_name_by_id ( id string ) -> string or inexistant_customer_error
// dummy implementation
if id =v "100"
return "Foo"
else
return inexistant_customer_error.create (
message = """Customer '{{id}}' doesn't exist."""
customer_id = id )
.
.In the next sections you'll see examples of error-handling approaches applied after calling customer_name_by_id. To illustrate each approach we'll write the body of a very simple function that takes a customer identifier as input, and writes the customer name to the standard OS out device. The function signature looks like this:
fn write_customer_name ( customer_id string )Before looking at error-handling approaches, let's first imagine the following implementation of write_customer_name:
fn write_customer_name ( customer_id string )
const name = customer_name_by_id ( customer_id )
write_line ( name )
.Would this code compile?
No, it wouldn't.
The type of constant name is inferred to be the union type string or inexistant_customer_error (the return type of function customer_name_by_id). Function write_line requires a string as input. But string or inexistant_customer_error isn't compatible with string — therefore the code doesn't compile.
The above code violates an essential rule introduced in section Fundamental Principles:
Errors returned by functions cannot be silently ignored.
We can't ignore the fact that a call to customer_name_by_id might fail. The compiler requires us to handle inexistant_customer_error in one way or another. Let's see how to do that.
Handling the Error
Suppose you simply want to write "Unknown customer" in case of an inexistant_customer_error. This can be done with a case type of statement:
fn write_customer_name ( customer_id string )
case type of customer_name_by_id ( customer_id )
is string as name
write_line ( name )
is inexistant_customer_error
write_line ( "Unknown customer" )
.
.Alternatively you could write:
fn write_customer_name ( customer_id string )
const result = customer_name_by_id ( customer_id )
if result is string then
write_line ( result )
else
write_line ( "Unknown customer" )
.
.You can use operator if_is to shorten the code:
fn write_customer_name ( customer_id string )
const name = customer_name_by_id ( customer_id ) if_is error: "Unknown customer"
write_line ( name )
.Or you can simply write:
fn write_customer_name ( customer_id string )
write_line ( customer_name_by_id ( customer_id ) if_is error: "Unknown customer" )
.Returning the Error
Quite often a function should simply propagate an error to its parent function in the call stack. In such cases, the error must be declared in its signature.
The code looks like this:
fn write_customer_name ( customer_id string ) -> inexistant_customer_error or null
case type of customer_name_by_id ( customer_id )
is string as name
write_line ( name )
return null
is inexistant_customer_error as error
return error
.
.This code works as follows:
-
If
customer_name_by_idreturns a string, then this string is written to STDOUT, andnullis returned. -
If
customer_name_by_idreturns an error, then this error is returned bywrite_customer_name. In other words, the error propagates up the call stack.
The on clause allows us to achieve the same with less code:
fn write_customer_name ( customer_id string ) -> inexistant_customer_error or null
const name = customer_name_by_id ( customer_id ) on error as e: return e
write_line ( name )
.Note that the type of constant name in the above code is inferred to be string.
Since on error as e: return e is used frequently, PTS provides the ^error shorthand:
fn write_customer_name ( customer_id string ) -> inexistant_customer_error or null
const name = customer_name_by_id ( customer_id ) ^error
write_line ( name )
.Returning a Wrapper Error
Sometimes a function should return a different error than the one obtained from a function call in its body. This is useful, for example, if you want to return a different error message, add additional context useful for the caller, or if you don't want to reveal the cause of the problem for security reasons (since detailed error messages can provide attackers with information they might exploit).
The following code illustrates how to return a higher-level error:
fn write_customer_name ( customer_id string ) -> runtime_error or null
case type of customer_name_by_id ( customer_id )
is string as name
write_line ( name )
return null
is inexistant_customer_error as error
return runtime_error.create (
message = "An error occurred."
cause = error // can be left off for security reasons
)
.
.Note
Here, we're assuming that runtime_error is a high level error defined in the standard library — a common parent for all types of anticipated errors that can occur at run-time.
Again, the on clause can be used to shorten the code:
fn write_customer_name ( customer_id string ) -> runtime_error or null
const name = customer_name_by_id ( customer_id ) \
on error as e: return runtime_error.create (
"An error occurred."
cause = e )
write_line ( name )
.Throwing an Unanticipated Error
it is better to crash early and suddenly than to slowly corrupt data on a long-term basis.
— Fred Hebert, The Zen of Erlang (video)
Sometimes, none of the parent functions in the call stack is able to handle an anticipated error in a meaningful way. Therefore, it doesn't make sense to let the error propagate. In such cases it is often better to fail fast. This can be done by throwing an unanticipated error, which is similar to throwing an (unchecked) exception in other languages.
Here's an example:
fn write_customer_name_or_throw ( customer_id string )
case type of customer_name_by_id ( customer_id )
is string as name
write_line ( name )
is inexistant_customer_error as e
throw program_error.create (
message = e.message
cause = e )
.
.Note the _or_throw suffix in the function name. By convention, this suffix is used for functions that might explicitly throw an unanticipated error.
Note
throw will be explained later in section throw Statement.
Instead of throwing a program_error, we could throw a customized error that inherits from unanticipated_error.
The on clause shortens the code:
fn write_customer_name_or_throw ( customer_id string )
const name = customer_name_by_id ( customer_id ) \
on error as e: throw program_error.create (
message = e.message
cause = e )
write_line ( name )
.The same effect can be achieved as follows:
fn write_customer_name_or_throw ( customer_id string )
const name = customer_name_by_id ( customer_id ) \
on error: throw
write_line ( name )
.A similar effect can be achieved with an assert statement:
fn write_customer_name ( customer_id string )
const result = customer_name_by_id ( customer_id )
assert result is not error
write_line ( result ) // result is guaranteed to be a string
.Aborting Program Execution
If you just want to quickly abort program execution in case of an anticipated error, you can do this:
fn write_customer_name ( customer_id string )
case type of customer_name_by_id ( customer_id )
is string as name
write_line ( name )
is inexistant_customer_error
write_line ( "Error: invalid customer id." )
OS_process.exit ( 1 )
.
.Note
Aborting program execution after encountering an anticipated error (as shown above) is often inacceptable in fault-tolerant applications — just imagine an operating system that shuts down at each error encountered, or a browser that aborts whenever an error occurs in a page.
In fault-tolerant systems, only a part of the application (e.g. the current operation, process, or thread) should be aborted in case of an unrecoverable error, and then be restarted. For a great insight into fault-tolerant systems, read The Zen of Erlang (or watch the video).
Explicitly Ignoring the Error
If you have a good reason to ignore an error, you can do so, but you need to be explicit, as shown below:
fn write_customer_name ( customer_id string )
case type of customer_name_by_id ( customer_id )
is string as name
write_line ( name )
is inexistant_customer_error
do nothing
.
.Note that the do nothing statement in the above code is required, because an is branch can't be empty. do nothing does exactly what it states: nothing. This statement clearly expresses the programmer's intent to ignore the error.
The try Statement
So far, we've seen different ways to handle a single error. If a function needs to handle several errors, then handling each error individually can lead to boilerplate, as shown below:
fn do_stuff -> stuff_error or null
task_1() on task_error as e: return stuff_error.create (
message = "An error occurred",
cause = e )
task_2()
task_3() on task_error as e: return stuff_error.create (
message = "An error occurred",
cause = e )
task_4() on task_error as e: return stuff_error.create (
message = "An error occurred",
cause = e )
.The above function suffers from code duplication, since the same code is repeated to handle errors returned by task_1, task_3, and task_4.
The try statement (borrowed from other languages) enables us to shorten the code, render it more maintainable, and separate the normal execution code (aka "the happy path") from the code that handles errors:
fn do_stuff -> stuff_error or null
try
try! task_1()
task_2()
try! task_3()
try! task_4()
on task_error as e
return stuff_error.create (
message = "An error occurred",
cause = e )
.
.Note the try! keyword in front of the statements that might fail. Without this keyword, you wouldn't be able to quickly track where errors can occur (and the IDE would no longer be able to help you spot these statements via syntax highlighting).
Unanticipated Errors
An unanticipated error is an error that is not expected to occur at run-time. Unanticipated errors occur if a serious problem arises during program execution — a problem that's not supposed to occur under normal conditions: e.g. a hardware malfunction, a problem in the OS, a configuration issue (e.g. missing library), a bug in the code. These errors can potentially occur at any time during program execution, and at any location in the source code.
They often occur due to a bug in the software. For example:
-
too deeply nested recursive function calls (or infinite recursions not detected by the compiler) lead to a
stack_overflow_error -
an infinite loop creating new in-memory objects results in an
out_of_memory_error -
violating the condition specified in an
assertstatement leads to anassert_violation_error(a child-type ofprogram_error) -
violating the pre-condition of a function input parameter leads to a
pre_condition_violation_error(also a child-type ofprogram_error) -
a bug in a function can lead to a
post_condition_violation_error(again, a child-type ofprogram_error)
Handling Unanticipated Errors
In PTS, unanticipated errors are handled similarly to unchecked exceptions in Java (i.e. child-types of RuntimeException), or exceptions in C#, Kotlin, and other languages.
Whenever an unanticipated error occurs, the error propagates upwards in the function call stack, until a function explicitly catches the error. If no function catches it, then a message is written to STDERR, and the application is aborted.
Global Error Handlers
By default, unanticipated errors are handled by one or more global unanticipated error handlers. A PTS implementation typically provides a single default handler which:
-
writes an error message and a trace of the function calls to the standard OS
errdevice (STDERR) -
aborts program execution with exit code
1
In an object-oriented implementation of PTS, the global error handler could be defined as a functional type (i.e. a type with one method):
type unanticipated_error_handler
fn handle_error ( error unanticipated_error )
.To customize global error handling, an application can register/unregister global error handlers. For example, an application could unregister the default error handler, register a handler that appends entries to a log file, and register another handler to send an email to the software developers, depending on the type of error encountered.
try Statement
Sometimes unanticipated errors need to be explicitly caught at strategically important locations in the source code, instead of letting them be handled by the global error handler(s).
Consider, for example, the development of a text editor. Suppose that an unanticipated error occurs after the user has typed a lot of unsaved text. The default error handler would simply write an unhelpful error message to the console, and then exit the application, which means that the user's work is lost. To avoid such frustrating situations, the text editor should at least save the current text to a temporary file, display a helpful error message to the user, and then exit gracefully.
There are many other situations requiring specific error handling for unanticipated errors, especially in fault-tolerant applications where random application shutdowns are unacceptable, since they could cause high damages.
To cover these situations, the try-catch-finally statement can be used to handle unanticipated errors in a customized way. This statement is similar to the try-catch-finally statement in other programming languages, where it's used to handle exceptions.
In section The try statement we already saw how this statement can be used to handle anticipated errors. Here's a reiteration of code from that section:
fn do_stuff -> stuff_error or null
try
try! task_1()
task_2()
try! task_3()
try! task_4()
on task_error as e
return stuff_error.create (
message = "An error occurred",
cause = e )
.
.And here's our new example, also using a try statement, but this time handling an unanticipated error:
try
do_this()
do_that()
catch unanticipated_error as e
// handle the error stored in constant 'e'
finally
// clean up (e.g. close resources)
.If you compare the latter code with the former, you can see that the on branch is used to handle anticipated errors, while the catch branch handles unanticipated errors.
The try-catch-finally statement works as follows:
-
If an unanticipated error occurs while executing the statements in the
trybranch, then the program immediately stops executing the remaining code in this branch, and jumps to the code inside thecatchbranch where the error is handled. -
The code in the
finallybranch is always executed. If no error occurs in thetrybranch, then thefinallybranch is executed immediately after, otherwise it's executed after thecatchbranch. Thefinallybranch is optional — it can be omitted if appropriate.
Both types of errors (anticipated and unanticipated) can be handled within a single try statement, using an on branch for anticipated errors, and a catch branch for unanticipated errors:
try
do_this()
do_that()
try! task_1()
task_2()
try! task_3()
try! task_4()
on anticipated_error as e
// handle anticipated errors
catch unanticipated_error as e
// handle unanticipated errors
finally
// clean up
.throw Statement
Most unanticipated errors are thrown implicitly, whenever a serious problem arises. For example, an out_of_memory_error is thrown implicitly when the memory on the host system is exhausted.
Sometimes it's useful to explicitly throw an unanticipated error. This is usually done whenever a function detects a serious problem that can't be handled, neither by the function itself, nor by any parent function in the call stack. The current operation, thread, process, or application must be aborted.
For example, consider an application that depends on some libraries being installed on the host. If the application discovers (at run-time) that a library is missing, it must abort execution.
Unanticipated errors can be thrown explicitly with a throw statement (also borrowed from other languages that support exceptions). The syntax of throw is as follows:
"throw" <expression><expression> must be of type unanticipated_error.
Here's a snippet illustrating the throw statement:
if third_party_libraries_missing then
throw program_error.create (
message = "Third-party libraries must be installed before using this application." )
.Explicitly thrown errors are handled exactly like their implicit counterparts: the error propagates up the call stack, and is either caught in a try-catch statement, or handled by the global error handler(s).
Practical Considerations
Error-handling is a vast topic — too vast to be fully covered in this article.
The best strategy for handling errors largely depends on the application domain and the potential damages in a worst-case error scenario.
Simply aborting program execution as soon as an error occurs might be an acceptable approach in a stamp-inventory application for personal use, but applying the same approach in mission-critical enterprise software would be irresponsible.
PTS is designed to always be on the safe side by default, because this helps to write reliable, robust, and fault-tolerant software. For example, anticipated errors returned by functions can't be ignored. However, this strict approach also means that code might end up being overly verbose and complex in applications that don't require the highest level of reliability, robustness, and fault-tolerance.
Obviously, it's impossible to provide one-size-fits-all "rules" for error-handling. However, in the following sections I'll provide some general guidelines (not rules set in stone) that might be useful.
Avoid Returning Many Types of Anticipated Errors!
Consider a high-level function named do_stuff that calls lower-level functions executing various read/write operations on files and directories. These low-level functions in the call tree return anticipated errors such as file_not_found_error, file_read_error, file_write_error, directory_read_error, directory_access_error. If each function in the tree propagates errors to its parent functions, then do_stuff might end up with a horrible signature like this:
fn do_stuff -> string or \
file_not_found_error or file_read_error or file_write_error or \
directory_read_error or directory_access_errorWorse, each time a signature in a lower-level function is changed later on (e.g. an error type is added or removed), the signatures of all parent functions (including do_stuff) need to be adapted accordingly.
While there are different solutions to avoid maintenance nightmares like this, a simple solution for higher-level functions is to just return a common parent type of all errors returned in the call tree. For example, do_stuff can be simplified as follows:
fn do_stuff -> string or directory_or_file_errorHere, we assume that directory_or_file_error is the parent type of all errors returned in the call tree.
Now suppose that, later on, database and network operations are added in the code. do_stuff needs to be adapted:
fn do_stuff -> string or directory_or_file_error or database_error or network_errorBut again, we can simplify by using a common parent type:
fn do_stuff -> string or IO_errorIn practice, using an appropriate parent type from the onset (e.g. IO_error) is often an acceptable solution, because:
-
It facilitates code maintenance.
-
Caller functions often don't care about which error occurred — they only care about whether an error occurred or not.
-
It hides implementation details which are irrelevant and might change in future versions.
It's important to note that error information is not lost if a higher-level function in the call-tree returns a higher-level error in the type hierarchy. For example, if a low-level function returns file_not_found_error, then a higher-level function declared to return IO_error still returns an instance of file_not_found_error (i.e. a child-type of IO_error), which can be explored by parent functions, or used for debugging/diagnostic purposes.
As a rule of thumb (that might be ignored if there is a good reason), functions shouldn't return many error types. It is often appropriate to declare a single error type which is a common parent type of all errors returned in the call tree. This leads to simpler and more maintainable code.
Use Wrappers if Appropriate!
There is another solution to the problem of "too many error types returned" explained in the previous section: define a dedicated error type that serves as a wrapper for all low-level errors, and return this wrapper in all low-level functions.
In our example, we could define type stuff_error, a wrapper for all errors in the call tree:
type stuff_error
inherit: runtime_error
.The signature of do_stuff becomes:
fn do_stuff -> string or stuff_errorLower-level functions also return stuff_error, and they store the source error (the cause) into attribute cause:
fn stuff_child -> null or stuff_error
...
const text = read_text_file ( file_path ) \
on file_read_error as e: return stuff_error.create (
message = e.message
cause = e )
...
.To shorten the code, we could define a creator/constructor create_from_cause for stuff_error (not shown here), and then simply write:
const text = read_text_file ( file_path ) \
on file_read_error as e: return stuff_error.create_from_cause ( e )Again, the low-level error information isn't lost, since it's stored in attribute cause of stuff_error.
See also: section Returning a Wrapper Error.
Use Unanticipated Errors if Appropriate!
Sometimes we don't want to handle errors — we assume the code to be running in an environment where errors aren't supposed to occur at run-time. If an error still occurs despite our assumption, then an immediate termination is appropriate: the application writes an error message to STDERR, and then aborts with exit code 1.
In other words, instead of handling an error, we opt to just abort execution instead. This is also referred to as panicking — for example, in Rust the panic! macro can be used to abort the application gracefully and release resources.
Aborting program execution in case of an error (i.e. panicking) is justified in various situations: for example, when experimenting with code, writing a prototype, building a personal stamp-inventory application, or when we just want to write quick and dirty code. Even in applications designed to handle errors, there might be specific cases where an immediate termination is preferable, for example to avoid corrupt data on a long-term basis. Good advice related to this topic is provided in chapter To panic! or Not to panic! of The Rust Programming Language.
While PTS is clearly not designed to abort by default, it does offer support for "crash early" approaches. You can abort (panic) if you have a good reason to do so — you just have to be explicit about it.
The basic idea is to convert anticipated errors into unanticipated ones every time you would have to deal with an anticipated error. Thus, instead of returning an anticipated error, you throw an unanticipated one. Let's see different ways to do this.
assert StatementA first technique is to use an assert statement to declare that an anticipated error isn't supposed to occur:
const result = customer_name_by_id ( customer_id )
assert result is not error
// continue with a customer object stored in 'result'on error: throw ClauseA better and less verbose technique is to use the on error: throw clause, which was introduced in section Throwing an Unanticipated Error:
const name = customer_name_by_id ( customer_id ) on error: throwWriting lots of on error: throw clauses can be annoying. A better solution might therefore be to write utility functions that throw unanticipated errors, instead of returning anticipated errors.
For example, suppose that many functions in our quick-and-dirty throw-away prototype read non-empty text files. Under normal circumstances (i.e. where reliability matters), we would call a library function like the following:
// returns 'null' if the file is empty
fn read_text_file ( file_path ) -> string or null or file_read_errorUsing this function requires checks for null and file_read_error in client code. To avoid these checks, we could define the following utility function, which assumes that file read errors don't occur and text files are never empty:
fn read_non_empty_text_file_or_throw ( file_path ) -> string (1)
case type of read_text_file ( file_path )
is string as content
return content
is null
throw program_error.create ( (2)
"""File {{path.to_string}} is empty.""" )
is file_read_error as e
throw program_error.create (
"""Could not read file {{path.to_string}} (3)
Reason: {{e.message}}""" )
.
.(1) By convention, the function name suffix _or_throw states that an unanticipated error might be thrown. Under normal conditions, the function returns a string containing the content of the non-empty text file.
(2) An unanticipated error is thrown if the file is empty.
(3) An unanticipated error is thrown if the file can't be read.
A simpler version of the above function could be written as follows:
fn read_non_empty_text_file_or_throw ( file_path ) -> string
const result = read_text_file ( file_path )
assert result is not null and result is not error
return result
.Client code is now simple and short, because null- and error-handling is no longer needed:
const text = read_non_empty_text_file_or_throw ( file_path.create ( "example.txt" ) )Sometimes it makes sense to use unanticipated errors in unexposed (private) parts of an application, because this can considerably simplify code and increase maintainability.
Suppose we are working on a complex parser with a main function like this:
fn parse ( string ) -> AST or syntax_errorSyntax errors are likely to be detected in low-level, private functions. Using anticipated errors in the whole call tree of function parse can easily lead to verbose code, because all errors need to be handled (e.g. propagated to the parent function) and declared in the function signatures. Whenever error types in function signatures change, a lot of refactoring might be required. To avoid this maintenance burden, it might be better to throw unanticipated errors in the functions called by parse, the root function in the call tree. Function parse uses a try statement to catch any unanticipated error, and converts it into an anticipated error which is then returned. The following simplified code illustrates this approach:
fn parse ( string ) -> AST or syntax_error
try
const AST = AST.create_empty
// parse the string and populate 'AST'
return AST
catch unanticipated_error as ue
return syntax_error.create ( message = ue.message )
.
.Warning
The above techniques that convert anticipated errors into unanticipated ones should usually not be used in public APIs (e.g. public functions in libraries, and frameworks).
Public APIs must be expressive and grant reliability. Public functions should return anticipated errors providing useful error information whenever something goes wrong. Consumers, not suppliers, decide how to handle errors.
However, there are rare exceptions to this rule. For example, it might be better (even in a public API) to abort instead of continuing execution with wrong/corrupted data. Such crash-early/fail-fast behavior should be clearly documented and, as suggested already, functions that might throw should have their name suffixed with _or_throw (e.g. do_it_or_throw).
Don't Use null to Return Error Conditions!
Suppose you're designing the map type (aka dictionary, associated_array) in a standard library. Method get takes a key as input and returns the corresponding value stored in the map. Here's an interesting question: What should the method do if the key doesn't exist?
It's tempting to simply return null, as is done in several libraries (e.g. Java Map.get). Using PTS syntax, map could be defined as follows:
type map<key_type child_of:hashable, value_type>
fn get ( key key_type ) -> value_type or null
// more methods
.There are two downsides to this approach:
-
If the values in the map are allowed to be
null(e.g.map<string, string or null>), an ambiguity arises.For example, if a method call like
map.get ( "foo" )returnsnull, it can mean two things: either there is no entry with key"foo", or there is an entry with key"foo"and valuenull. -
If the values in the map aren't allowed to be
null(e.g.map<string, string>), there's a risk of misinterpretation.For example, if a method call like
map.get ( "foo" )returnsnull, it could erroneously be interpreted in the client code as an entry with key"foo"and valuenull.This risk for misinterpretation increases if a map with nullable values is later on changed to a map with non-null values (e.g. from
map<string, string or null>tomap<string, string>).
To eliminate the first problem (ambiguity when null is returned), we can add method contains_key (which is needed anyway):
type map<key_type child_of:hashable, value_type>
fn contains_key ( key key_type ) -> boolean
fn get ( key key_type ) -> value_type or null
// more methods
.This works, because we can now call contains_key to eliminate the ambiguity. But it doesn't work well. Firstly, method get is error-prone, because one has to read the docs, be careful, and not forget to call contains_key if get returns null. Secondly, calling get first, and contains_key afterward, is verbose and can result in very nasty bugs in case of race conditions caused by sharing a mutable map in concurrent or parallel processing environments.
This error-proneness vanishes if get returns an error (instead of null) whenever a key isn't contained in the map:
type map<key_type child_of:hashable, value_type>
fn get ( key key_type ) -> value_type or key_not_contained_in_map_error
// more methods
.Client code is now required to check for key_not_contained_in_map_error, e.g.
const value = map.get ( "foo" ) on error as e: return eWe are protected from forgetting to check if the key actually exists in the map. Moreover, the fact that method get could fail is also clearly expressed in the client code.
However, being forced to check for an error can be annoying, and leads to verbose code. If a key isn't contained in the map, you might want to:
-
throw an unanticipated error, because you assume that the key ought to be contained in the map
-
fallback to a default value
-
get
null, because you don't need to differentiate between the two possible meanings ofnull
These use cases can easily be covered by adding variations of the get method:
type map<key_type child_of:hashable, value_type>
fn get ( key key_type ) -> value_type or key_not_contained_in_map_error
fn get_or_throw ( key key_type ) -> value_type
fn get_or_default ( key key_type, default value_type ) -> value_type
fn get_or_null ( key key_type ) -> value_type or null
// more methods
.Providing many choices is sometimes counterproductive, but in this case it is justified by the fact that map is a fundamental data structure, defined in the standard library, and used in many different ways.
Besides providing a more versatile API, we benefit from the following:
-
The behavior of the four getter methods is clearly expressed by their signatures — the programmer probably doesn't need to read the docs to know which getter method to use (although he/she must still be aware of the potentially ambiguous meaning in the case of
nullbeing returned byget_or_null). -
Client code is succinct in all cases and auto-documents the behavior in case of a non-existent
key. Here are a few examples:const value_1 = map.get ( "foo" ) ^error const value_2 = map.get_or_throw ( "foo" ) const value_3 = map.get_or_default ( key = "foo", default = "bar" ) const value_4 = map.get_or_null ( "foo" ) if value_4 is null then // handle it .
Summary
Here's a brief summary of PTS error-handling rules and built-in support:
-
There are two types of errors:
-
anticipated errors (e.g.
file_not_found_error,invalid_data_error) -
unanticipated errors (e.g.
out_of_memory_error,stack_overflow_error)
-
-
Anticipated errors:
-
are expected to possibly occur at run-time
-
must be declared as a function return type (using union types)
-
must be handled in one way or another, or explicitly ignored
-
-
Unanticipated errors:
-
are not expected to occur at run-time
-
can potentially occur at any time, and at any location in the source code
-
are either handled by one or more global error handlers or caught and handled explicitly anywhere in the source code
-
can be thrown implicitly or explicitly
-
-
A set of commonly used anticipated and unanticipated error types are defined in the standard library. Additional, domain-specific error types can be defined in a software development project, to cover specific needs.
-
PTS provides a set of dedicated operators and statements to facilitate error-handling.
Acknowledgment
Many thanks to Tristano Ajmone for his useful feedback to improve this article.