Suggestion For a Better XML/HTML Syntax

Introduction
XML is a great technology with many useful, standardized, and well-supported extensions like XML schemas, XPath, XQuery, XSLT, etc. However, XML has a reputation of being too verbose. This doesn't come as a surprise if we look at one of the design goals stated in the official W3C XML Recommendation:
Terseness in XML markup is of minimal importance.
XML specification
An interesting question arises: "Couldn't we keep the technology, but just improve the syntax to make XML and HTML easier to read and write for humans?"
This article shows that the answer to this question is a resounding "Yes, we can!".
We'll have a look at a suggestion for a new syntax that is less verbose, easy to read and write, and works well for all kinds of XML documents, including HTML code.
Readers of this article are supposed to have a basic knowledge of XML, HTML, and JSON.
As this article is about XML, the term "HTML" used here implicitly refers to XML-compliant HTML (i.e. XHTML).
Existing Alternatives
Before trying to invent anything new we should of course first have a deep look at what exists already.
This chapter answers the question: Is there any existing markup language with a more human-friendly syntax than XML/HTML, but also well suited for big, complex, and changing documents?
JSON
In the last years, JSON has overtaken XML in terms of popularity.
To understand why (in the context of syntax), let's have a look at a simple data structure in JSON:
{
"person": {
"name": "Albert",
"married": true,
"address": {
"street": "Kramgasse",
"city": "Bern"
},
"phones": [ "123", "456"]
}
} In XML, the code could look like this:
<?xml version="1.0" encoding="UTF-8"?>
<person>
<name>Albert</name>
<married>true</married>
<address>
<street>Kramgasse</street>
<city>Bern</city>
</address>
<phones>
<phone>123</phone>
<phone>456</phone>
</phones>
</person>Many people prefer the JSON syntax. It is easier to read and less verbose than the XML version. Not counting indentation spaces, the above JSON code requires 144 characters to type. The XML code has 276 characters. That's an increase of 92%!
Examples like the above one lead to an intriguing question:
-
"Couldn't we just stop using XML and use JSON instead for everything?"
For example, could we use the JSON syntax to write HTML documents?
Let's try.
Here is a simple HTML snippet:
<p>foo bar</p>In JSON, we could express this as follows:
{ "p": "foo bar" }Let's write foo in italics, and bar in bold.
HTML:
<p><i>foo</i> <b>bar</b></p>JSON:
{ "p": [ { "i":"foo" }, " ", { "b": "bar" } ] }Now we want to display everything in red:
HTML:
<p style="color:red;"><i>foo</i> <b>bar</b></p>JSON:
{ "p": { "style": "color:red;", "content": [ { "i": "foo" }, " ", { "b": "bar" } ] } }We can prettify to make the code easier to read:
{
"p":{
"style":"color:red;",
"content":[
{
"i":"foo"
},
" ",
{
"b":"bar"
}
]
}
} But now the HTML one-liner has mutated into a '14 lines monster with lots of horizontal and vertical whitespace'.
Not quite what we are looking for.
Besides the obvious fact that the complexity of the JSON code increases quickly, there is another worrying observation:
-
In the first example, the
pelement's value was a string:"p": "...". -
In the second example, the value becomes a JSON array:
"p": [...]. -
In the last example, it mutates to a JSON object:
"p": {...}.
Such changes can easily lead to maintenance nightmares. Code that inspects the data structure must be updated each time the code changes. For example if we wanted to extract the text of element p, we would need to write different code for the three cases.
XML doesn't have this problem. The content of p is always a list of child elements.
At this point you hopefully agree that we can stop further investigation and move on. The JSON syntax is a bad fit for describing markup code like HTML documents in a human-friendly way. That doesn't mean of course that 'JSON is bad'. JSON is a good choice in many cases. It is a native part of JavasSript, well-supported in most programming languages, and there are lots of libraries and tools available for JSON. However, in the context of our search for a better markup syntax, JSON (as well as all variations of it) is not an option. Later we'll have a look at a more complete HTML example that confirms our conclusion.
YAML
One way to minimize verbosity is to use indentation to define structure. YAML is probably the most popular language that uses this technique.
Here is a reprint of a JSON example we saw previously:
{
"person": {
"name": "Albert",
"married": true,
"address": {
"street": "Kramgasse",
"city": "Bern"
},
"phones": [ "123", "456"]
}
} In YAML, this becomes:
person:
name: Albert
married: true
address:
street: Kramgasse
city: Bern
phones:
- 123
- 456Nice!
Easy to read and write.
At first sight it might seem that we could use such a noise-less syntax for all kinds of data structures, including markup code.
It turns out that would be a very bad idea. The problem with YAML and all other languages that use indentation to define structure is this: It works well for small, simple structures (such as config files). But if we need to manage big documents with deeply nested structures then it quickly becomes error-prone and unmaintainable.
Moreover, while using indentation to define structure effectively reduces verbosity, it also leads to much more lines of code for certain types of documents. The reason is that each child element must be written on a new line.
To illustrate this, let's see how the simple HTML one-liner we used in the previous chapter would be written in YAML. Here is a reprint of the HTML:
<p style="color:red;"><i>foo</i> <b>bar</b></p>In YAML the code would look like this:
p:
style: 'color:red;'
content:
- i: foo
- ' '
- b: barThere are other arguments against whitespace-sensitive documents, such as the problems with mixing spaces and tabs, and code snippets that cannot be shared between different documents with different levels of indentation. These inconveniences are well known - there is no need for repetition here.
Finally, the whitespace-significant approach forces us to use whitespace according to the rules (which can get very complex). It takes away the freedom to use whitespace to make documents more appealing and understandable.
As for JSON, this doesn't mean that 'YAML is bad'. YAML is well suited in some cases. What I want to say is that the idea of using whitespace-sensitivity in a markup language like HTML is doomed to fail. It's understandable that, according to Wikipedia, the meaning of the acronym YAML was changed from "Yet Another Markup Language" to "YAML Ain't Markup Language".
XML/HTML ignores whitespace, and that's the right choice.
Other
Several other markup languages exist, but I am not aware of any syntax that would be well suited to replace the XML syntax. If you know of a good alternative then please leave a comment.
There are also many tools and editor plugins aiming to alleviate the pain of writing XML code by hand. However, the gist of this article is not to alleviate the pain. We want to remove it.
New Syntax
In this chapter I will suggest a new, alternative syntax for XML/HTML documents. The new syntax should be practical for humans and machines. So let's call it practicalXML, or just pXML.
Elements
Simple Element
Let's start with the following HTML snippet - a simple element that contains only text:
<i>foo</i>The first thing we need to do is to get rid of the closing tag syntax (</i>) - the biggest culprit of XML's verbosity. We can do this by just closing the element with >, like this:
<i>foo>This creates an imbalance of < and > symbols. But that's easy to fix. We replace the > in the opening tag with a space - the easiest character to read and write on any keyboard. The code becomes:
<i foo>Let's think about the brackets. We could use <>, as in XML/HTML. But there are other options: [], {}, and (). We need to consider two points:
-
How easy are they to type?
[]clearly wins, because on most keyboards (including Dvorak keyboards) all other brackets require theShiftkey to be hold down. -
How often do they occur in normal text?
This is important because the brackets have to be escaped in normal text. I didn't find any reliable statistics, but my guess would be that
()is used often, while the others are used rarely, maybe in this order:{},[], and<>.
The best option is to use [], because this pair is easy to write (no need for Shift on most keyboards), and square brackets rarely occur in normal text. Moreover, it creates a clear distinction between the new pXML syntax ([]), XML/HTML (<>), and source code (which often uses {}).
Hence, the final pXML code becomes:
[i foo]... which is easier to read and write than:
<i>foo</i>Another advantage of the new syntax is that bracket matching in text editors (available in most modern versions) becomes more useful. For XML/HTML, the < of the opening tag matches only the > of the opening tag, which is of little use. In VSCode it looks like this:
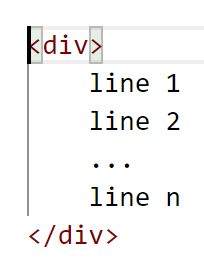
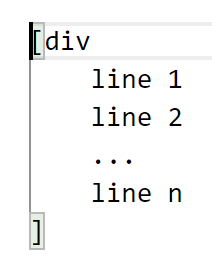
In pXML the [ of the opening tag matches the ] of the closing tag, which is much more helpful, especially in case of elements with lots of nested content. VSCode example:
Empty Element
An empty XML element is an element that has no attributes and no child nodes.
A typical example is the br element used to insert a new line in an HTML document. Here is the code:
<br /> <!-- XML-compliant -->
<br> <!-- not XML-compliant -->In pXML, this is written as:
[br]Child Elements
An XML element can optionally contain one or more child elements. They are embedded within the opening and closing tags. Here is an example:
<table>
<tr><td>Cell 1.1</td><td>Cell 1.2</td></tr>
<tr><td>Cell 2.1</td><td>Cell 2.2</td></tr>
</table>There is no reason to change this in pXML. The above example is written like this:
[table
[tr [td Cell 1.1][td Cell 1.2]]
[tr [td Cell 2.1][td Cell 2.2]]
]Closing Tags
When nested elements are closed, we often see HTML code like this:
</img></div></section>If indentation is used, it looks like this:
</img>
</div>
</section>In pXML the code without indentation becomes:
]]]With indentation:
]
]
]While the new syntax obviously improves writing-speed and reduces the size of code, it also creates two inconveniences:
-
The code becomes less understandable, especially in case of big, nested elements.
-
In case of a missing
](i.e. we forget to close an element) or a superfluous], the error message generated by the parser risks being less helpful. For example, imagine a superfluous]in the middle of a big document. The parser will only be able to detect the error at the end of the document, and report a superfluous]at the last line.Note, however, that this problem can be largely mitigated when elements are indented, and the parser emits a warning if the indentation of the opening
[and closing]are different.
To eliminate these inconveniences we should support an alternative, more verbose syntax to close elements.
Obvious options like [/tag] or tag] don't work, because they create an imbalance of brackets, or they require special rules for exceptional corner cases. I finally opted for the following alternative syntax:
][/tag]Hence, the above code to close three elements can optionally be written like this:
][/img] ][/div] ][/section]... or this
][/img]
][/div]
][/section]This is a bit more verbose than the XML syntax, because there is one more character per closing tag. But it is also a bit easier to write because the Shift key doesn't have to be used twice. In practice the verbose syntax is only needed to close big tags with many levels of child elements. So I think the alternative pXML syntax to close tags is a good compromise. It's there if you need it, and it works well (no corner cases that require special rules).
Name Rules
For compatibility reasons, the rules for element names in pXML must be the same as in XML. Element names:
-
are case-sensitive
-
must start with a letter or underscore
-
cannot start with "xml"
-
can contain letters, digits, hyphens, underscores, and periods
-
cannot contain spaces
Escape Rules
pXML uses the backslash (\ ) as escape character.
Three characters must always be escaped in text:
| Character | Escape Token |
|---|---|
| [ | \[ |
| ] | \] |
| \ | \\ |
The following code shows how the text Watch out for <, >, ", ', &, [, ], and \ characters must be escaped in XML and pXML:
XML: <note>Watch out for <, >, ", ', &, [, ], and \ characters</note>
pXML: [note Watch out for <, >, ", ', &, \[, \], and \\ characters]Any Unicode character can be inserted by using the \uhhhh syntax commonly used in programming languages. For example the text:
Hell\u006fis parsed as:
HelloXML entities are currently not supported in pXML.
In XML, "a < 1" is parsed as a < 1. In pXML it is parsed as "a < 1"
However, if a pXML document is converted to an XML document (or XML to pXML), the conversion automatically applies the correct escape rules. For example, the following pXML text:
\[ <... will be converted to the following XML text:
[ <... and vice versa.
Attributes
Overview
Besides elements, XML also supports attributes. Here is an example of an XML element with attributes:
<div id="unplug_warning" class="warning big-text">Unplug power cord before opening!</div>In pXML, the same code looks like this:
[div ( id=unplug_warning class="warning big-text" ) Unplug power cord before opening!]As can be seen, the two syntaxes are similar. There are two obvious differences:
-
In pXML, attributes are embedded in parentheses:
(...). The syntax is like function argument assignments in some programming languages. -
In pXML, attribute values don't always need to be quoted (e.g.
id=unplug_warning).
Names
In XML, attribute names are not quoted (unlike in JSON), and they must respect the same rules as we previously saw for element tag names.
To stay compatible with XML, pXML applies the same rules. Attribute names:
-
must start with a letter or underscore
-
can contain letters, digits, hyphens, underscores, and periods (no spaces)
Values
In XML, attribute values must always be quoted with ". Example: name = "Bob".
In pXML, values can be unquoted, double-quoted, or single-quoted.
Unquoted value
Values are not required to be quoted if they don't contain:
-
whitespace:
<space>, <tab>, <carriage return>, <line feed> -
square brackets:
[ and ] -
parenthesis:
( and ) -
quotes:
" and '
Examples:
name = Bob
port = 8080
path = C:\Users\AliceDouble-quoted and single-quoted value
If a value contains any of the characters not allowed in unquoted values, then the value must be surrounded by double-quotes (") or single-quotes (').
Examples:
food = "healthy orange" // contains space
expression = "array[17]" // contains square brackets
conclusion = "It's ok." // contains '
statement = 'He said: "All is well".' // contains "Escape rules
Escape sequences are not supported in unquoted attribute values. Therefore parsing unquoted values is a bit faster.
Escaping is supported for double-quoted and single-quoted values. The following rules are applied:
-
A backslash (
\) is used to start an escape sequence. -
Double quotes must be escaped in double-quoted values with
\". Example:statement = "He said: \"All is well\"." // He said: "All is well". -
Single quotes must be escaped in single-quoted values with
\'. Example:conclusion = 'It\'s ok.' // It's ok. -
A backslash must be escaped with
\\. Example:path = "C:\\Users\\Alice" // C:\Users\Alice -
The following values can optionally be escaped:
Name Syntax square brackets \[ \] tab \t carriage return \r line feed \n -
Any Unicode character can be inserted by using the
\uhhhhsyntax commonly used in programming languages. Example:word = "Hell\u006f" // Hello
New lines
For better readability, attribute assignments can be written on separate lines, like this:
[image (
source = images/kid.png
title = "Kid is flabbergasted"
width = 800px
height = 600px
)]Whitespace between attribute assignments is ignored.
Quoted values can contain new lines. Example:
statement = 'He said: // He said:
"All is well!"' // "All is well!" If new lines are inserted literally in the code, as in the above example, then the actual new line character(s) parsed depend on the operating system, as well as the editor/program configuration used to create the code. By default:
-
On Unix/Linux, a new line is a single <line feed> character
-
On Windows, a new line is composed of two characters: a <carriage return> and <line feed>
On both systems, this default behavior might be overridden. For example, a Windows editor can be configured to produce a single <line feed> character for new lines inserted in the code.
To force a specific new line in pXML code, we can use an escape sequence in the code, e.g.:
statement = 'He said:\r\n"All is well!"' // Windows new line forced
statement = 'He said:\n"All is well!"' // Unix new line forcedDifferences between XML and pXML
In pXML, writing:
[e (a1=v1 a2=v2)]is semantically equivalent to:
[e [a1 v1][a2 v2]]In both cases, node e is a node with two child nodes: a1 and a2. The API to access the content of e is the same in both cases.
pXML attributes just provide an alternative syntax for child nodes.
The alternative syntax is useful because it is better suited for sets of child nodes that contain only text.
Here is a node not using attributes:
[image [source ball.png][width 300px][height 200px]]The same node defined with attributes looks like this:
[image (source=ball.png width=300px height=200px)]The second version (using attributes) is slightly shorter, easier to read and write, and more familiar to people used to the XML attributes syntax. However, both versions are parsed into the same tree structure.
This contrasts with XML, where attributes and elements are different. In XML, the API used to access attributes is different from the API for child elements. Hence, a program that reads an XML structure must know if a value is an attribute or an element. Moreover, if a value that was initially defined as an attribute, is later defined as an element (or vice versa), then the program that reads the value must be updated. This is not necessary in pXML.
Comments
An XML comment looks like this:
<!-- text of comment -->We can simplify by using [- to start a comment, and -] to stop it. Here is the pXML version:
[- text of comment -]There is no ambiguity with [- being the start of an element with name - because, according to the rules, an element name cannot contain hyphens (-).
Nested comments are often useful in practice. For example, it's common to comment a block of code that contains already a comment. Therefore pXML supports nested comments (unlike XML). Here is an example:
[- text of outer comment
[- text of inner comment -]
-]Applications that convert pXML to XML code must be careful to not convert inner comments, because XML doesn't support nested comments. The above comment cannot be converted to:
<!-- text of outer comment
<!-- text of inner comment -->
-->It should be converted to:
<!-- text of outer comment
[- text of inner comment -]
-->Other
The following XML syntax constructs are not covered in this introductory article: XML entities, namespaces, CDATA sections, and processing instructions. They might be the subject of a follow-up article.
History
pXML Predecessor
When I started to ponder about the new syntax, I didn't think at all about creating a better XML/HTML syntax. What I wanted was a new syntax to write articles (published on a blog) and books. Initially I used Docbook, then Asciidoctor to write articles. I also tried out Markdown, and had a look at other syntaxes like RestructedText. To make a long story short: I felt frustrated with some impracticalities of existing solutions, and finally decided to design a new syntax called Practical Markup Language (PML). If you want to know more about my motivation to create PML, you can read We Need a New Document Markup Language - Here is Why (published in March 2019). (Note: For readers still using a word processor, I also wrote Advantages of Document Markup Languages vs WYSIWYG Editors)
Nowadays, I write all my articles in PML (including this one). To publish them I created a PML to HTML Converter which reads a PML file and creates an HTML file. You can have a look at the PML source of this article here, and you can see the original version of it here (i.e. the result produced by the PML to HTML Converter). Right-click on the original article, and click 'View Page Source' if you want to have a look at the HTML code produced by the PML to HTML Converter. The converter produces indented, clean and simple HTML code, like hand-coded. The PML to HTML Converter is open-sourced under the GPL2, and written in PPL (Practical Programming Language). The source code is on GitHub.
After creating PML, I suddenly realized that it's syntax could also be used to write XML/HTML documents - a nice side effect. This article is my first step in making my idea public.
One could say that PML is to pXML like HTML is to XML. PML uses the pXML syntax, but only predefined, semantic PML tags are allowed.
Lenient Syntax in PML
An important aspect of PML is the parser's ability to work in lenient mode. This mode supports targeted syntax simplifications, aiming to eliminate as much "noise" as possible. It should be easy to write articles and books in PML. Here is an example to illustrate the advantage of the lenient syntax:
This is the code of a simple PML document, written in strict pXML:
[doc (title=Test)
[ch (title="An Unusual Surprise")
[p Look at the following picture:]
[image (source=images/strawberries.jpg)]
[p Text of paragraph 2]
[p Text of paragraph 3]
]
]In lenient PML mode (always activated), the text can be shortened to:
[doc Test
[ch An Unusual Surprise
Look at the following picture:
[image images/strawberries.jpg]
Text of paragraph 2
Text of paragraph 3
]
]Let's briefly see how this works:
-
doc (title=Test)becomesdoc Test:Some elements (for example
doc) have a default attribute. For that attribute only the value needs to be specified - instead of writing(name=value)we can simply writevalue -
[p Text of paragraph 2]becomesText of paragraph 2:Free text not contained in an element is automatically embedded in a
p(paragraph) element.Text separated by two new lines automatically creates a paragraph break.
If you want to try the above code, you can proceed like this:
-
Download the PML to HTML Converter
-
Create file
example.pmlin any directory, with the PML code shown above (the strict pXML version will not work). -
Copy a picture to
resources/images/strawberries.jpg -
Open a terminal in the directory of file
example.pmland typepmlc example.pml
-
Open file
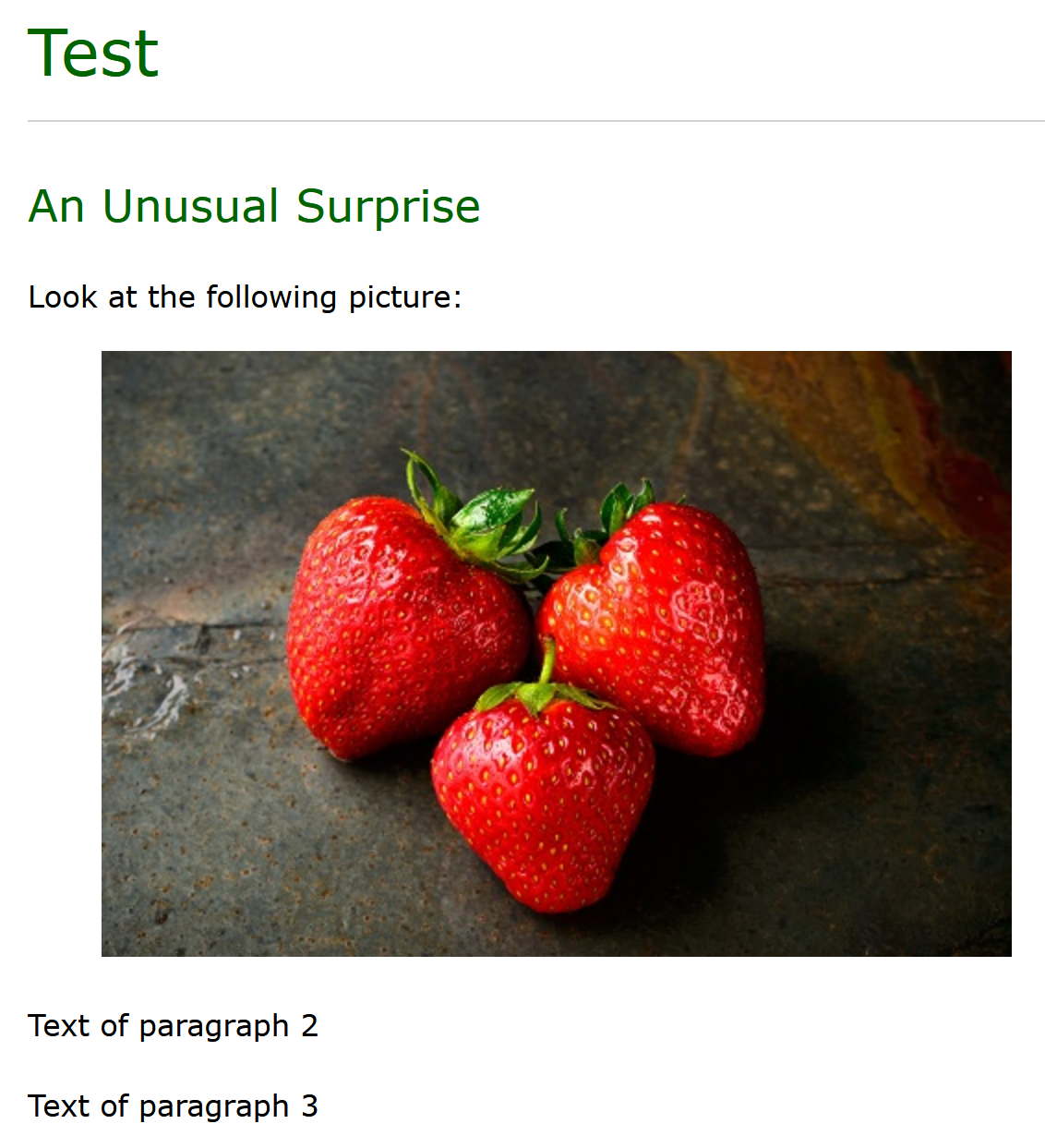
output/example.htmlin your browser.The result looks like this:
-
Right-click on the text, and select 'View Page Source' if you want to see the HTML code produced by the PML to HTML Converter.
Implementation
After using the PML syntax for some time to create real articles (not just tests), I was somewhat confident that the pXML syntax should work well for XML documents too. However, to eliminate doubts, I wanted a proof of concept for pXML, before publishing this article. Therefore, I created a parser that reads the pXML syntax presented in this article. The parser is written in Java and has no dependencies. I will open-source it.
The following features are currently implemented:
-
Convert pXML into XML (pXML/XML escape rules are applied)
-
Convert XML into pXML (pXML/XML escape rules are applied)
-
Read a pXML document into an
org.w3c.dom.DocumentJava object.This is the most powerful feature. Since we have a Java
Documentobject we can use all of XML's related specifications with a pXML document. A few examples are:-
validate a document with XML Schema (W3C), RELAX NG, or Schematron
-
programmatically traverse the document
-
insert, modify, and delete elements and attributes, and save the result as a new XML or pXML document
-
query the document (search for values, compute aggregates, etc.) with XQuery/XPath
-
convert the document using an XSL transformer (e.g. create a differently structured XML document, create a plain text document, etc.)
-
Here is a "Hello World" example of a pXML to XML conversion:
-
Suppose we created file
hello.pxmlwith this content (an empty root element with namehello):[hello] -
The following Java code converts this pXML file into an XML file named
hello.xml:PXMLToXMLConverter.PXMLFileToXMLFile ( new File("hello.pxml"), new File("hello.xml") ); -
The resulting
hello.xmlfile looks like this:<?xml version="1.0" encoding="UTF-8"?> <hello />
The opposite (i.e. converting an XML file to a pXML file) can be done with:
XMLToPXMLConverter.XMLFileToPXMLFile ( new File("hello.xml"), new File("hello.pxml") );
Once the pXML parser is ready to be open-sourced (planned for May 2021), I'll publish a dedicated article with more examples.
I'm also working on a dedicated pXML website with a syntax specification and the grammar expressed in EBNF and railroad diagrams. Everybody is very welcome to participate in an open-source project.
Examples
A picture is worth a thousand words. So let's look at two common examples: a simple config file, and HTML code. We will compare code written in JSON, XML, pXML, and PML.
Simple Config File
A simple config file is just a (possibly nested) map of key/value pairs.
JSON
Here is an example in JSON:
{
"size":"XL",
"colors":{
"background":"black",
"foreground":"light green"
},
"transparent":true
}Remarks:
The need for quoting names and values is a bit annoying.
Another inconvenience is the comma required at the end of each assignment, except the last one. Each time we add a parameter at the end of a list, there is a risk of forgetting to add a comma at the existing second-last line.
XML
The same config data look like this in XML:
<config>
<size>XL</size>
<colors>
<background>black</background>
<foreground>light green</foreground>
</colors>
<transparent>true</transparent>
</config>Remark: The closing tags are noisy.
Alternative syntax, using attributes:
<config>
<size>XL</size>
<colors background="black" foreground="light green" />
<transparent>true</transparent>
</config>Remark: Both syntaxes are not API-compatible. The change of using attributes instead of elements requires an update of the code that accesses the values of colors.
pXML
The pXML version looks like this:
[config
[size XL]
[colors
[background black]
[foreground light green]
]
[transparent true]
]Alternative syntax, using attributes:
[config
[size XL]
[colors (background=black foreground="light green")]
[transparent true]
]Remark: Both syntaxes are API-compatible. The change of using attributes instead of elements does not require an update of the code that accesses the values of colors.
Verbosity
To compare the verbosity of the three syntaxes, let's consider the length of the markup code needed for one parameter (excluding whitespace):
| Language | Markup | Length | Range | Remark |
|---|---|---|---|---|
| JSON | "":"", | 6 | 3 to 6 | -2 for integer, boolean, and null values (because they are not quoted); -1 for the last parameter (because it doesn't have a trailing comma) |
| XML element | <></size> | 9 | min. 6 | The length depends on the number of characters in the name |
| XML attribute | ="" | 3 | always 3 | |
| pXML element | [] | 2 | always 2 | |
| pXML attribute | = or ="" | 1 or 3 | 1 or 3 | The length is 1 if the value doesn't need to be quoted |
Conclusion
The most verbose syntax is XML (especially for long parameter names). The least verbose one is pXML. Less noise implies 'easy to read and write for humans'.
HTML Code
Now we'll look at some HTML code - the most common use of XML. To keep the example short, we'll just look at an HTML snippet, leaving off the HTML header and footer.
HTML
The following code represents a chapter with three paragraphs and a picture:
<section>
<h2>Harmonic States</h2>
<p>The <i>initial</i> state looks like this:</p>
<img src="images/state_1.png" />
<p>After just a few <i><b>micro</b>seconds</i> the state changes.</p>
<p>More text ...</p>
</section>JSON
In a previous chapter we saw already that JSON is not a good fit to write HTML-like code. Nevertheless, let's a have look at the JSON version of our HTML snippet - just to confirm our previous conclusion:
{ "section": [
{ "h2": "Harmonic States" },
{ "p": [ "The ", { "i": "initial" }, " state looks like this:" ] },
{ "img": { "src": "images/state_1.png" } },
{ "p": [ "After just a few ", { "i": [ { "b": "micro" }, "seconds" ] }, " the state changes." ] },
{ "p": "More text ..." }
] }If we prettify, the 7 lines of code turn into 38 (!) lines with more whitespace than text:
{
"section":[
{
"h2":"Harmonic States"
},
{
"p":[
"The ",
{
"i":"initial"
},
" state looks like this:"
]
},
{
"img":{
"src":"images/state_1.png"
}
},
{
"p":[
"After just a few ",
{
"i":[
{
"b":"micro"
},
"seconds"
]
},
" the state changes."
]
},
{
"p":"More text ..."
}
]
}Who would enjoy writing and maintaining code like this? Yet this is just a simple toy example. Imagine a code base with real-world, big and complex HTML code!
pXML
This is the pXML version:
[section
[h2 Harmonic States]
[p The [i initial] state looks like this:]
[img (src=images/state_1.png)]
[p After just a few [i [b micro]seconds] the state changes.]
[p More text ...]
]PML
As said already, PML has a lenient syntax mode that allows for succinct markup code:
[ch Harmonic States
The [i initial] state looks like this:
[image images/state_1.png]
After just a few [i [b micro]seconds] the state changes.
More text ...
]If we embed the above code in a doc element (as shown before), save the code into file test.pml, and run the PML to HTML Converter with the OS command pmlc test.pml, a complete HTML file is created (with header and footer). Here is an excerpt of this file (CSS code removed):
<section id="ch__1">
<h2>Harmonic States</h2>
<p>The <i>initial</i> state looks like this:</p>
<figure>
<img src="images/state_1.png" />
</figure>
<p>After just a few <i><b>micro</b>seconds</i> the state changes.</p>
<p>More text ...</p>
</section>As can be seen, it is very similar to the initial HTML code we would write by hand.
Verbosity
Let's look at numbers. How much effort does it take to write the code in the four languages? If we extract the markup code (i.e. remove whitespace and text displayed in the browser) we get this, from worst to best:
JSON: {"section":[{"h2":""},{"p":["",{"i":""},""]},{"img":{"src":""}},{"p":["",{"i":[{"b":""},""]},""]},{"p":""}]}
HTML: <section><h2></h2><p><i></i></p><imgsrc=""/><p><i><b></b></i></p><p></p></section>
pXML: [section[h2][p[i]][img(src=)][p[i[b]]][p]]
PML: [ch[i][image][i[b]]]Counting the number of characters gives us the following table:
| Language | Markup length | Percentage of HTML |
|---|---|---|
| JSON | 108 | 132% |
| HTML | 82 | 100% |
| pXML | 42 | 51% |
| PML | 20 | 24% |
A graph of these numbers looks like this:
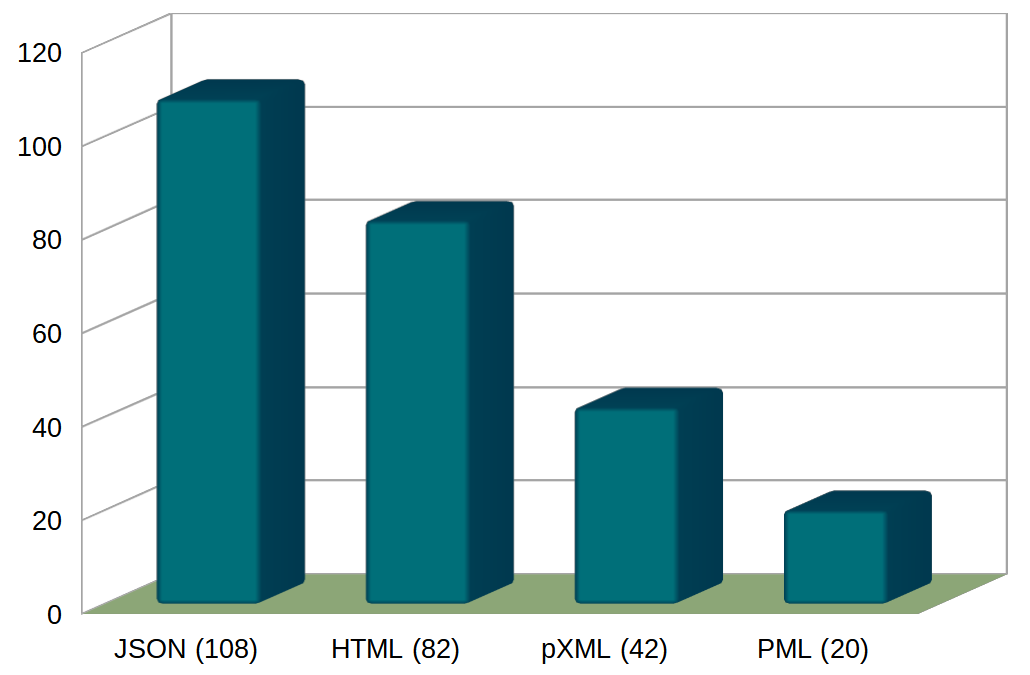
Of course this is not a representative result. Other HTML examples would lead to more or less different numbers. However, it clearly shows the impact of syntax. Syntax affects complexity, space and time, and usability. Succinct syntax makes it easier and more enjoyable to read and write code.
Syntax Comparison
Here is a brief comparison of the XML vs pXML syntax:
Empty element:
XML: <br />
pXML: [br]Element with text content:
XML: <summary>text</summary>
pXML: [summary text]Element with child elements:
XML: <ul>
<li>
<div>A <i>friendly</i> dog</div>
</li>
</ul>
pXML: [ul
[li
[div A [i friendly] dog]
]
]Attributes:
XML: <div id="unplug_warning" class="warning big-text">Unplug power cord before opening!</div>
pXML: [div (id=unplug_warning class="warning big-text")Unplug power cord before opening!]Escaping:
XML: <note>Watch out for <, >, ", ', &, [, ], and \ characters</note>
pXML: [note Watch out for <, >, ", ', &, \[, \], and \\ characters] Comments:
Single comment:
XML: <!-- text -->
pXML: [- text -]
Nested comments:
XML: not supported
pXML: [- text [- nested -] -]Summary And Conclusion
As demonstrated, it is possible to simplify the XML syntax and make it more accessible for humans.
The pXML syntax introduced in this article essentially suggests three changes:
-
Replace the XML syntax:
<name>value</name>... with:
[name value]
-
Embed attributes between parenthesis and allow unquoted values if possible.
The XML code:
name1="value" name2="value with spaces"... becomes:
(name1=value name2="value with spaces") -
Support for nested comments (not supported in XML)
Although the pXML syntax is less verbose and different from XML, all great additions that are part of the XML ecosystem can still be used. Once a pXML document is parsed into an XML tree, documents can be validated, queried, modified, and transformed.
Well-designed syntax increases productivity, reduces errors, eases maintenance, and improves space and time efficiency.
Syntax matters!
Article History
-
2021-03-10: First version
-
2021-04-20:
-
added attributes syntax
-
removed optional name prefix
#(used to differentiate between data and metadata)
-